Git Worktree: o padrão para tocar múltiplas features e rodar agentes em paralelo
Várias árvores de trabalho, um só repositório. Como o git worktree elimina a troca de contexto destrutiva, roda vários agentes de IA em paralelo e por que venceu o clone manual.
Você está no meio de uma feature, com dez arquivos modificados e o dev server rodando. Aí chega o "dá uma olhada rápida nesse PR" ou o "tem um bug em produção, resolve agora". O que acontece em seguida é sempre a mesma dança: git stash, trocar de branch, esperar o node_modules reconstruir, reiniciar o server, resolver o problema, voltar, git stash pop e torcer pra não ter conflito.
Essa fricção toda tem nome de solução: git worktree. E em 2026, com agentes de IA trabalhando em paralelo, ela deixou de ser um truque de power user para virar parte do fluxo básico.
O que é, em uma frase
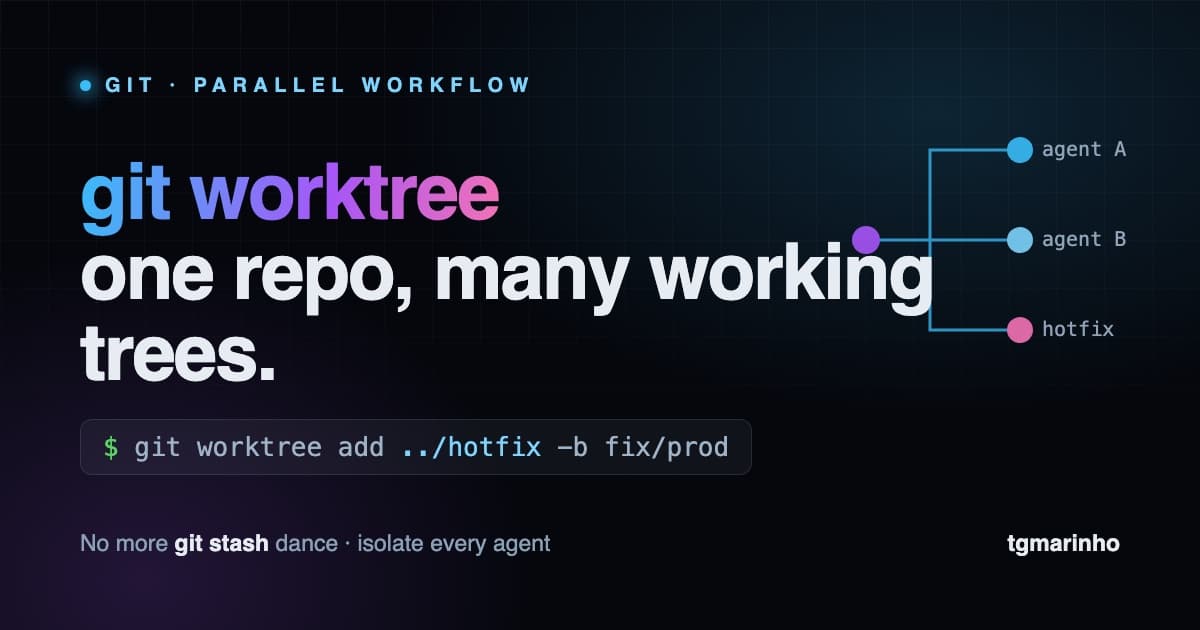
Um repositório Git normal tem uma árvore de trabalho (working tree) ligada a um .git. O git worktree permite ter várias árvores de trabalho apontando para o mesmo repositório: cada uma em uma pasta diferente, cada uma em uma branch diferente, todas compartilhando o mesmo histórico e os mesmos objetos.
Na prática: em vez de trocar de branch dentro da mesma pasta, você tem várias pastas, cada uma "parada" na sua branch. Sem stash. Sem perder estado.
Os comandos que importam
Criar um worktree novo em uma pasta irmã, já numa branch nova:
git worktree add ../hotfix -b fix/login-500Isso cria a pasta ../hotfix com a branch fix/login-500 pronta para uso. Você abre outro terminal (ou outra janela do editor) lá e trabalha sem tocar na sua pasta principal.
Listar o que existe:
git worktree listQuando terminar, remova:
git worktree remove ../hotfixE, de tempos em tempos, limpe referências órfãs (pastas que você apagou na mão):
git worktree pruneSão basicamente quatro comandos. O retorno sobre esse investimento é absurdo.
O fluxo na prática
Hotfix sem perder o WIP. O cenário do começo do post vira trivial: git worktree add ../hotfix -b fix/prod, resolve lá, abre o PR, e sua feature continua intacta com o server rodando na outra pasta.
Revisar um PR de verdade. Em vez de dar checkout na branch dos outros e bagunçar seu ambiente, crie um worktree, rode, teste, leia. Sua branch nem fica sabendo.
Builds longos em paralelo. Deixe um worktree compilando/rodando testes pesados enquanto você continua codando em outro. São processos isolados em pastas isoladas.
O motivo de 2026: agentes em paralelo
Aqui está o que mudou o jogo. Quando você roda vários agentes de IA ao mesmo tempo (um implementando a feature, outro escrevendo testes, outro investigando um bug), eles não podem dividir a mesma pasta. Dois agentes editando os mesmos arquivos na mesma working tree é receita para corrupção de estado e conflitos impossíveis de depurar.
A solução é dar a cada agente o seu próprio worktree: mesma base de código, histórico compartilhado, mas árvores de trabalho isoladas. Cada agente trabalha na sua branch, na sua pasta, sem pisar no pé do outro. No fim, você revisa e faz merge.
Não é teoria, e ficou muito mais fácil. Ferramentas como o Conductor orquestram exatamente isso: um worktree por workspace de agente, criado e descartado automaticamente. Combinado com um editor leve como o Zed, você abre cada worktree em sua própria janela e acompanha os agentes lado a lado. O Codex também ganhou suporte de primeira classe a worktrees: cria uma worktree nova (em modo detached) para cada thread de conversa, roda o setup do ambiente e oferece um "hand off to local" para trazer as mudanças de volta. Rodar várias tarefas em paralelo deixou de exigir gambiarra de shell.
O que parecia um detalhe obscuro do Git virou a fundação do desenvolvimento com múltiplos agentes, e as ferramentas finalmente esconderam o trabalho braçal.
Comparando variações em paralelo
Um uso que só fica óbvio depois que você experimenta: pedir a mesma tarefa para vários agentes ao mesmo tempo e comparar os resultados. Quer redesenhar uma página? Suba três worktrees e peça três direções diferentes (futurismo, brutalismo, minimalismo), uma por agente. Cada worktree roda seu próprio dev server em uma porta diferente (5171 para a main, 5172 e 5173 para as variações), e você navega entre elas lado a lado antes de decidir qual versão merge.
Como tudo compartilha o mesmo .git, o merge da versão escolhida é local: você nem precisa dar push pro GitHub. Uma worktree enxerga as branches criadas na outra, então dá pra consolidar o trabalho sem depender de conexão externa.
Worktree vs. clonar o repo
"Mas eu já faço isso clonando o repo em outra pasta." Funciona, mas é mais pesado e desconectado:
- Espaço em disco. Cada
git cloneduplica todo o histórico (a pasta.git). Worktrees compartilham um único.git; só os arquivos da branch são extraídos. - Merge local. Entre clones, trazer uma mudança de uma pasta para outra normalmente passa por push + pull num servidor central. Entre worktrees, o merge é local e imediato.
- Visibilidade.
git worktree listmostra todas as árvores e em que branch cada uma está. Com clones, você navega pasta por pasta pra descobrir o que está rolando.
Resumo: clone é um universo isolado; worktree é uma extensão leve do mesmo repositório.
.env e dependências: o detalhe que trava todo mundo
O ponto onde a maioria tropeça: como .env, segredos e node_modules estão no .gitignore (ou simplesmente não são versionados), o Git não copia nada disso para a worktree nova. Você abre a pasta, roda o projeto e faltam variáveis de ambiente.
A solução é automatizar. Um padrão comum é um script de postinstall no package manager (no caso do Bun, atrelado ao bun install) que localiza o .env no repositório principal e copia para a worktree assim que as dependências terminam de instalar. Ferramentas como o Codex permitem configurar "environments" que rodam esse setup sozinhos a cada nova thread, ou seja, a cada nova worktree.
E lembre: o que você copiou na mão some junto quando a worktree é removida. O node_modules e o .env daquela pasta vão embora com o git worktree remove.
O gargalo real: banco e infra, não o código
Vale ser honesto sobre o limite. Worktree isola a árvore de código, mas não isola o estado. Frontend, SDK e lógica de aplicação você paraleliza tranquilo, porque são arquivos. O problema aparece embaixo, na infra: todas as worktrees costumam apontar para o mesmo banco, as mesmas filas, os mesmos serviços externos.
Aí dois agentes rodando migrations divergentes na mesma base, ou um seed que muda linhas que o outro lê, voltam a colidir, só que agora no dado, não no arquivo. Feature flag ajuda a isolar comportamento na camada de aplicação, mas não isola schema nem dado.
A resposta para "tem banco versionado?" é: mais ou menos, e está melhorando.
- Branching de banco. Neon, PlanetScale, Supabase e Turso fazem branch do banco por cópia copy-on-write. Cada worktree (ou cada preview deploy) ganha sua própria cópia isolada, que você descarta depois. É o equivalente de worktree para o Postgres.
- Git para dados. O Dolt leva semântica de Git literal para tabelas SQL: branch, commit, merge e diff de linhas, não só de schema.
- Banco efêmero por worktree. O básico que sempre funciona: um Postgres em container por worktree, em porta diferente, com seed próprio. Ou SQLite embarcado, um arquivo por pasta.
- Migrations versionadas. Prisma, Drizzle, Flyway: o schema vive no Git e viaja com a branch. Mas isso versiona a estrutura, não os dados nem o estado em produção.
Resumindo: worktree resolve o código de graça; o banco e a infra você ainda precisa isolar de propósito. A combinação que está virando padrão é worktree para o código mais branching de banco para o estado, um par por feature ou por agente.
As pegadinhas
Vale conhecer os limites antes de tropeçar neles:
- A mesma branch não pode estar em dois worktrees ao mesmo tempo. O Git bloqueia isso de propósito, pra você não ter duas árvores divergindo na mesma referência.
- Rode o install em cada worktree. Cada uma é uma pasta de verdade no disco, com seu próprio
node_modules. Um package manager com cache global como o Bun deixa isso rápido. - Limpe quando terminar. Worktrees abandonados acumulam. Use
removeeprune. Alguns apps fazem faxina sozinhos (o Codex remove worktrees antigas ou em excesso, a menos que a conversa esteja fixada), mas no terminal a limpeza é com você.
Conclusão
O git worktree resolve um problema que todo dev tem mas aprendeu a tolerar: a troca de contexto destrutiva. Quatro comandos, e você deixa de escolher entre "terminar o que estava fazendo" e "atender a urgência". Você vira um gerente de múltiplos fluxos em vez de um executor sequencial.
E com agentes trabalhando em paralelo, ele deixou de ser conveniência para virar requisito. Se você ainda faz a dança do stash, é hora de mudar.
Referência: vídeo sobre git worktree do Augusto Galego.
Escrito por IA, revisado por Thiago Marinho
27 de abril de 2026 · Brazil