HTTP QUERY: o método seguro com body agora é RFC 10008
HTTP QUERY agora é RFC 10008: entenda quando usar o novo método seguro com body, como ele difere de GET e POST e quais cuidados adotar em APIs reais.
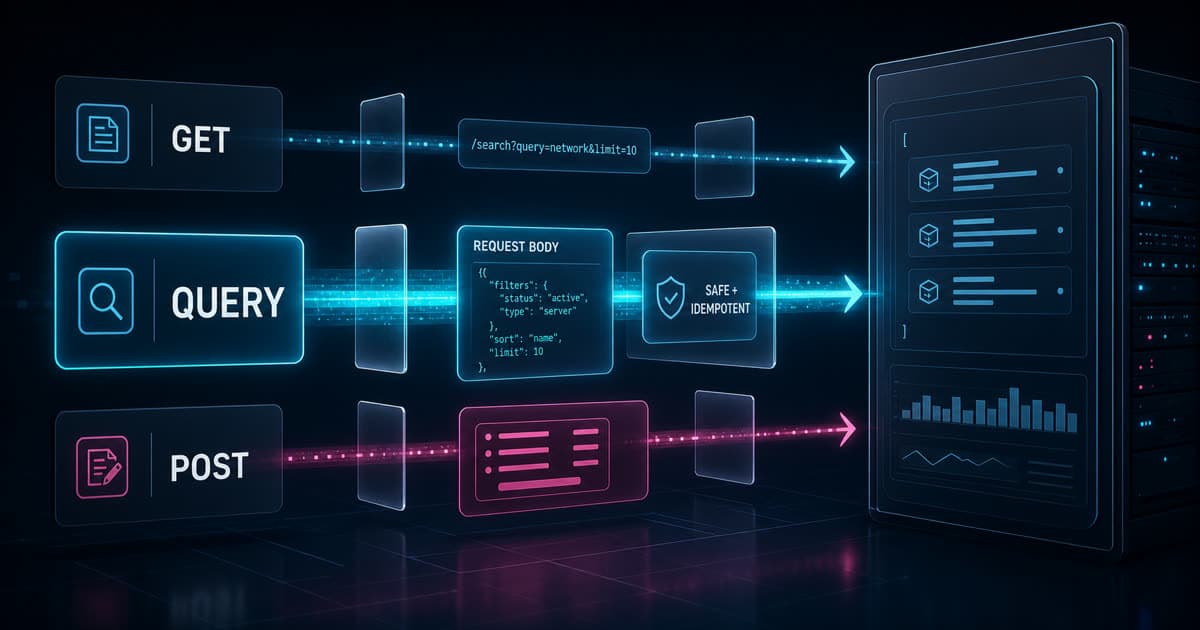
HTTP QUERY é o novo método HTTP padronizado no RFC 10008 para consultas seguras e idempotentes com corpo de requisição. Ele resolve o espaço entre GET, que coloca os parâmetros na URI, e POST, que aceita body mas não comunica que a operação é apenas leitura.
O ponto prático é simples: se a sua API precisa consultar dados com filtros complexos, mas não quer transformar isso em uma ação de escrita, QUERY dá uma semântica mais honesta para o protocolo.
O que é HTTP QUERY?
QUERY é um método para pedir que o recurso alvo processe o conteúdo enviado no body de forma segura e idempotente, e responda com o resultado desse processamento.
Em HTTP, seguro significa que o cliente não está pedindo uma mudança de estado no recurso alvo. Idempotente significa que repetir a mesma requisição deve ter o mesmo efeito esperado. Isso permite retentativas automáticas, reinício de conexão e uma relação mais clara com cache.
Um exemplo:
QUERY /contacts HTTP/1.1
Host: api.example.com
Content-Type: application/json
Accept: application/json
{
"select": ["name", "email"],
"where": {
"company": "example.com",
"status": "active"
},
"limit": 20
}A diferença não está no formato JSON. Está no contrato: isto é uma consulta, não uma criação, atualização ou comando escondido dentro de POST.
Por que GET não bastava?
GET continua sendo o melhor método para buscar uma representação simples de um recurso. O problema aparece quando a consulta vira uma estrutura grande, aninhada ou sensível demais para caber bem na URI.
O próprio RFC 10008 cita alguns problemas comuns:
| Problema com GET | Efeito prático |
|---|---|
| Limite de tamanho de URI varia entre clientes, proxies e servidores | A requisição pode quebrar antes de chegar na aplicação |
| Estruturas aninhadas precisam ser serializadas na URL | A API fica frágil e difícil de ler |
| URIs costumam aparecer em logs, histórico e favoritos | Filtros e dados sensíveis ficam mais expostos |
| Cada combinação de parâmetros parece um recurso diferente | Cache e identificação de recurso ficam mais difíceis de modelar |
Para filtros simples, use GET. Para consultas complexas com corpo, QUERY passa a ser a opção semanticamente correta.
Por que POST não era ideal?
POST aceita body e por isso virou a saída comum para buscas complexas. GraphQL, RPCs HTTP e endpoints de busca muitas vezes usam POST mesmo quando a operação é leitura.
Funciona, mas perde sinal semântico. Para um cliente, proxy, cache, gateway ou biblioteca genérica, POST pode significar processamento com efeito colateral. Sem conhecimento específico daquele endpoint, não fica claro que repetir a requisição é seguro.
Compare:
| Método | Body | Seguro | Idempotente | Uso típico |
|---|---|---|---|---|
| GET | Sem semântica definida para body | Sim | Sim | Buscar recurso por URI |
| QUERY | Esperado | Sim | Sim | Consultar com body |
| POST | Esperado | Nem sempre | Nem sempre | Submeter processamento ou criar algo |
O ganho de QUERY é tornar explícito algo que antes dependia de documentação: este body descreve uma consulta segura.
Como cache e retentativas entram nisso?
Cacheability é uma das razões mais importantes para QUERY. O RFC 10008 define QUERY como seguro, idempotente e cacheável, com regras próprias para mapear a consulta para um recurso equivalente.
Na prática, isso permite que um servidor responda com cabeçalhos como Content-Location ou Location para dar uma URI ao resultado ou à consulta equivalente. Depois disso, um cliente pode buscar aquele resultado com GET quando fizer sentido.
Exemplo simplificado:
QUERY /search HTTP/1.1
Host: api.example.com
Content-Type: application/json
Accept: application/json
{ "q": "http query", "limit": 10 }Resposta:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Location: /search/results/abc123
Cache-Control: public, max-age=300Esse desenho preserva duas ideias ao mesmo tempo: o cliente envia uma consulta rica no body, e o servidor ainda pode dar identidade HTTP ao resultado.
Como descobrir se um endpoint aceita QUERY?
Accept-Query é o header definido pelo RFC 10008 para anunciar quais formatos de consulta um recurso aceita.
Uma resposta pode indicar suporte assim:
Accept-Query: application/json, application/x-www-form-urlencodedIsso é importante porque o método sozinho não define a linguagem da consulta. O body pode ser JSON, form urlencoded, JSONPath, SQL restrito, uma DSL interna ou outro formato. O Content-Type precisa ser explícito, e o servidor deve rejeitar conteúdo sem tipo ou com tipo inconsistente.
Uma regra prática para implementação:
| Caso | Status sugerido |
|---|---|
Sem Content-Type | 400 Bad Request |
| Tipo de mídia não suportado | 415 Unsupported Media Type |
| Body inconsistente com o tipo | 400 Bad Request |
| Consulta válida, mas impossível de processar | 422 Unprocessable Content |
Accept pede resposta não suportada | 406 Not Acceptable |
Quando usar QUERY em uma API?
Use QUERY quando a operação tiver estas três propriedades:
- É leitura ou consulta.
- Precisa de body para expressar filtros, seleção de campos, ordenação, paginação ou uma linguagem de consulta.
- Pode ser repetida sem criar, alterar ou excluir estado no recurso alvo.
Bons candidatos:
- Busca com filtros aninhados.
- Relatórios consultivos sem efeito colateral.
- Query de catálogo com muitas facetas.
- APIs internas que hoje usam
POST /searchsó para carregar filtros. - Endpoints onde retentativa automática é desejável.
Evite QUERY quando a operação:
- Cria recurso.
- Altera estado.
- Dispara workflow.
- Registra comando de negócio.
- Depende de efeitos colaterais observáveis.
Se existe efeito colateral solicitado pelo cliente, ainda é POST, PUT, PATCH ou DELETE.
Quem se beneficia do QUERY?
Os maiores beneficiados por QUERY são times que hoje usam POST para consultas complexas e pagam o custo semântico disso. O método ajuda quando a operação é leitura, mas a entrada é rica demais para uma URI.
| Quem se beneficia | Por quê |
|---|---|
| Designers de API | Ganham um método correto para busca complexa com body |
| Frontend e mobile | Podem enviar filtros ricos sem montar URLs enormes |
| SDKs e clientes HTTP | Conseguem separar melhor consulta segura de comando |
| Gateways, proxies e CDNs | Podem aplicar política, cache e retry com mais contexto |
| Observabilidade | Logs, traces e métricas passam a distinguir leitura complexa de mutação |
| GraphQL, RPC e tRPC | Ganham uma possível semântica HTTP melhor para procedures de leitura |
| Agentes de IA e ferramentas de código | Conseguem inferir intenção de endpoint com menos documentação implícita |
Quem menos se beneficia são APIs simples de CRUD, onde GET já descreve bem a consulta, e sistemas onde proxies, clientes ou gateways ainda bloqueiam métodos novos. Nesses casos, QUERY pode esperar.
O que muda para REST, GraphQL, RPC, gRPC e tRPC?
API design ganha uma opção que antes não existia de forma padronizada: consulta com body, sem fingir que a operação é POST.
| Estilo | Antes de QUERY | O que muda com QUERY |
|---|---|---|
| REST | GET para busca simples, POST para busca complexa com body | QUERY /resources pode representar busca complexa sem efeito colateral |
| GraphQL | POST para quase tudo, GET para query pequena ou persisted query | Query operations poderiam usar QUERY no futuro, mas a especificação e os clientes precisam adotar |
| RPC HTTP | Muitas chamadas usam POST mesmo para leitura | Métodos read-only podem ganhar transporte mais claro, sem abandonar o modelo RPC |
| gRPC | Protocolo é definido sobre HTTP/2 com POST | Não muda no curto prazo. gRPC é um contrato próprio sobre HTTP/2 |
| tRPC | Queries costumam usar GET ou POST, mutations usam POST | QUERY seria um bom transporte para procedures de leitura com input grande |
Para REST, a mudança é direta. Muitos endpoints como POST /search, POST /reports/query ou POST /products/filter existem só porque GET não carrega bem filtros grandes. Esses endpoints poderiam virar QUERY /search ou QUERY /products.
Para GraphQL, a mudança é conceitualmente atraente, mas não automática. A prática atual do GraphQL over HTTP é aceitar POST, e permitir GET para operações de query. QUERY combina bem com GraphQL query operations porque elas são leitura com body. Mesmo assim, Apollo, Relay, gateways, CDNs, ferramentas de persistência e a especificação GraphQL over HTTP precisariam tratar isso como transporte oficial antes de uso amplo.
Para RPC genérico, QUERY ajuda quando existe separação real entre procedimentos de leitura e comandos. Um UserService.searchUsers sem efeito colateral é candidato. Um InvoiceService.closeInvoice não é.
Para gRPC, eu não esperaria mudança rápida. gRPC não é apenas "RPC usando HTTP". Ele define framing, trailers, content type application/grpc, status próprio e mapeamento sobre HTTP/2. O método POST faz parte desse contrato. A mudança mais provável não é gRPC trocar POST por QUERY, mas protocolos RPC mais HTTP-friendly, como Connect, explorarem melhor métodos seguros para chamadas idempotentes.
Para tRPC, o encaixe é natural porque já existe diferença semântica entre query e mutation no modelo do framework. Hoje o transporte HTTP usa GET e POST. Uma versão futura poderia mapear query com input grande para QUERY, mantendo mutation em POST.
O que muda em HTTP/1.0, HTTP/1.1, HTTP/2 e HTTP/3?
HTTP semantics são separadas da versão de transporte. QUERY é um método HTTP, então a ideia vale para HTTP/1.1, HTTP/2 e HTTP/3. O que muda é a chance de a infraestrutura aceitar o método sem bloqueio.
| Versão | Como o método aparece | Impacto prático |
|---|---|---|
| HTTP/1.0 | Linha textual: QUERY /search HTTP/1.0 | Funciona em teoria, mas é o ambiente mais arriscado por proxies antigos |
| HTTP/1.1 | Linha textual: QUERY /search HTTP/1.1 | É o caso mais simples de entender, mas middleboxes podem bloquear métodos novos |
| HTTP/2 | Pseudo-header :method = QUERY | O framing aceita método como semântica HTTP, mas bibliotecas e gateways precisam reconhecer |
| HTTP/3 | Mesmo modelo semântico do HTTP, transportado sobre QUIC | O risco fica em bibliotecas, gateways e políticas de borda, não no nome do método |
Em HTTP/2, não existe uma request line textual como em HTTP/1.1. O método vai no pseudo-header :method. Isso reduz ambiguidade de parsing, mas não elimina política de produto. Um gateway pode continuar permitindo só GET, POST, PUT, PATCH e DELETE.
Também existe um detalhe de server push em HTTP/2: clientes podem rejeitar push de métodos que não reconhecem como seguros. Como QUERY tem body e server push não carrega request content, isso não é o caso principal de uso.
Como frameworks e linguagens devem se adaptar?
Interoperabilidade é o cuidado principal. O método está padronizado, mas a internet real passa por clientes, runtimes, proxies, firewalls, gateways, CDNs, observabilidade e bibliotecas que podem bloquear métodos novos.
O histórico do Node mostra bem o problema. Em janeiro de 2024, uma issue relatou que node:http respondia 400 Bad Request para QUERY porque o parser não aceitava o método. Isso não era só detalhe de aplicação. Era suporte na camada HTTP.
O padrão de adaptação deve seguir esta ordem:
- Parser HTTP aceita
QUERY. - Roteador permite registrar handler para
QUERY. - Body parser lê request body nesse método.
- Cliente HTTP consegue enviar
QUERYcom body. - CORS, cache, OpenAPI, tracing, WAF e CDN entendem a semântica.
| Camada | O que provavelmente muda |
|---|---|
| Java | HttpClient já tem method(String, BodyPublisher). Frameworks como Spring podem usar @RequestMapping quando o enum suportar ou quando houver extensão |
| Go | net/http aceita método customizado via http.NewRequest e roteamento por ServeMux moderno |
| Node.js | O parser precisa aceitar o método. Depois disso, http, fetch, Express, Fastify e Nest podem rotear |
| Spring | O caminho natural é suporte em RequestMethod e documentação para @RequestMapping com body |
| NestJS | Pode precisar de decorator próprio, porque @Query() já significa query params. O nome provável teria que evitar confusão |
| Express | Tende a seguir a lista de métodos suportados pelo pacote de métodos e pelo Node usado |
| Fastify | Já tem extensão explícita via addHttpMethod, inclusive com hasBody |
| Apollo e Relay | Precisariam tratar QUERY como transporte GraphQL válido, não apenas GET ou POST |
| Fetch | QUERY não é método proibido, mas não é CORS-safelisted. Em cross-origin, espere preflight |
| OpenAPI | OpenAPI 3.2 já documenta query como operação |
Exemplo em Java:
HttpRequest request = HttpRequest.newBuilder(URI.create("https://api.example.com/search"))
.header("Content-Type", "application/json")
.method("QUERY", HttpRequest.BodyPublishers.ofString(json))
.build();Exemplo em Go:
req, err := http.NewRequest("QUERY", "https://api.example.com/search", body)E, em servidores com ServeMux moderno:
mux.HandleFunc("QUERY /search", queryHandler)Exemplo em Fetch:
await fetch("https://api.example.com/search", {
method: "QUERY",
headers: {
"Content-Type": "application/json",
"Accept": "application/json",
},
body: JSON.stringify({ filters: { status: "active" }, limit: 20 }),
});Exemplo em Fastify:
fastify.addHttpMethod("QUERY", { hasBody: true });
fastify.route({
method: "QUERY",
url: "/search",
handler: async (request, reply) => {
return reply.send(await search(request.body));
},
});No JavaScript de browser, o cuidado maior é a combinação entre Fetch, Cross-Origin Resource Sharing, service workers, gateways e infraestrutura. Antes de expor QUERY em API pública, teste o caminho inteiro:
- Cliente HTTP.
- Runtime do servidor.
- Proxy reverso.
- Load balancer.
- CDN.
- WAF ou firewall.
- Logs, tracing e métricas.
O método ser RFC não garante que toda ferramenta no caminho já trate QUERY como comum.
Como eu implementaria hoje?
Eu começaria com adoção controlada. Para API pública, manteria GET e POST funcionando onde eles já são necessários, e adicionaria QUERY primeiro em endpoints onde o ganho semântico é claro.
Um plano seguro:
- Escolha um endpoint de busca que hoje usa POST, mas é leitura.
- Implemente
QUERYcom o mesmo contrato de body. - Exija
Content-Type. - Retorne
Accept-Query. - Defina cache só quando a variação pelo body estiver bem modelada.
- Teste cliente, proxy, CDN e logs.
- Documente fallback para POST enquanto a infraestrutura amadurece.
Exemplo com curl:
curl -X QUERY https://api.example.com/search \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
--data '{"filters":{"status":"active"},"limit":20}'Para produto real, eu também adicionaria testes de integração passando pela mesma porta HTTP usada em produção. Não basta chamar o handler direto. O risco está no caminho de rede.
Qual é a regra prática?
A regra é: use GET quando a URI descreve bem a consulta, use POST quando a operação pode ter efeito colateral, e use QUERY quando a consulta precisa de body mas continua sendo segura e idempotente.
QUERY é pequeno como mudança de sintaxe, mas grande como sinal de protocolo. Ele permite que API, cliente e infraestrutura entendam a intenção da requisição sem depender de convenção local.
Referências
- RFC 10008: The HTTP QUERY Method
- HTTPWG draft: The HTTP QUERY Method
- Node.js issue #51562: Support for QUERY method
- Kevin McDonald: HTTP QUERY and Go
- RFC 9110: HTTP Semantics
- RFC 9113: HTTP/2
- Fetch Standard
- GraphQL: Serving over HTTP
- gRPC over HTTP/2
- tRPC HTTP RPC Specification
- OpenAPI 3.2 HTTP Methods
- Java HttpRequest.Builder
- Spring Request Mapping
- Fastify addHttpMethod
Resumo: QUERY é o método HTTP para consulta segura com body. Ele não substitui GET ou POST. Ele dá semântica correta para buscas complexas que hoje usam POST apenas porque GET não carrega bem esse tipo de entrada.
Escrito por IA, revisado por Thiago Marinho
21 de junho de 2026 · Brazil