HTTP QUERY: the safe method with a body is now RFC 10008
HTTP QUERY is now RFC 10008: learn when to use the safe method with a body, how it differs from GET and POST, and what to check before shipping in real APIs.
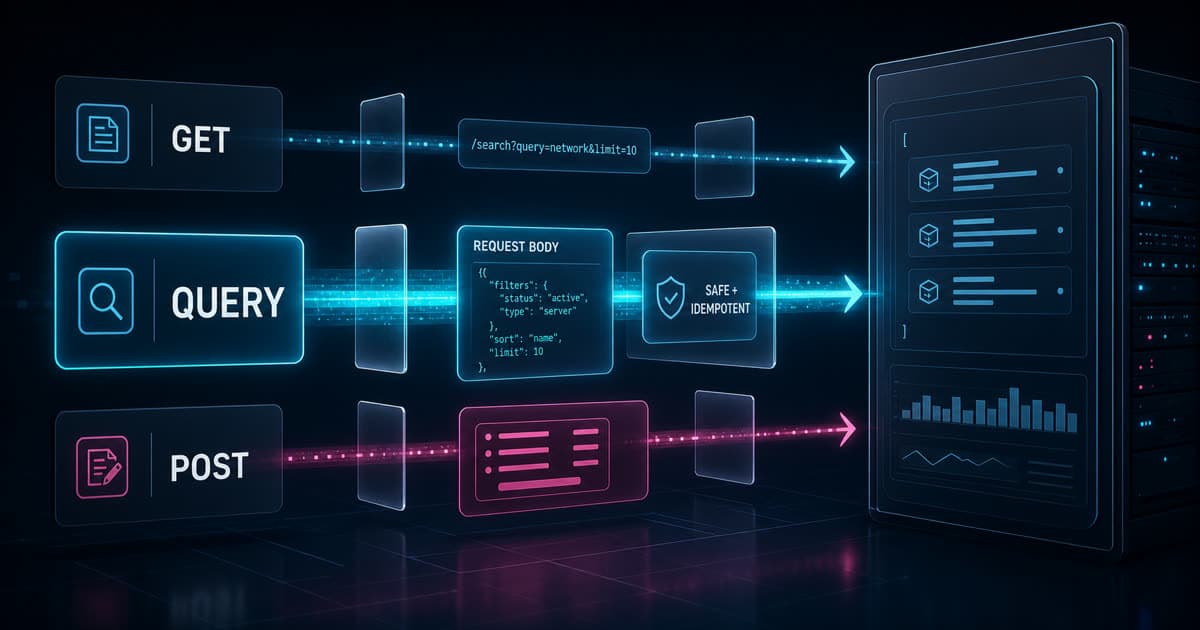
HTTP QUERY is the new HTTP method standardized in RFC 10008 for safe, idempotent queries with a request body. It fills the gap between GET, which puts query input in the URI, and POST, which accepts a body but does not say the operation is read-only.
The practical point is simple: if your API needs complex filters without turning a read into a write-like action, QUERY gives the protocol a more honest signal.
What is HTTP QUERY?
QUERY is a method that asks the target resource to process the request body in a safe and idempotent way, then return the result of that processing.
In HTTP, safe means the client is not asking to change the state of the target resource. Idempotent means the same request can be repeated with the same expected effect. This makes automatic retries, connection restarts, and caching behavior easier to reason about.
Example:
QUERY /contacts HTTP/1.1
Host: api.example.com
Content-Type: application/json
Accept: application/json
{
"select": ["name", "email"],
"where": {
"company": "example.com",
"status": "active"
},
"limit": 20
}The important part is not JSON. It is the contract: this is a query, not a create, update, or command hidden inside POST.
Why was GET not enough?
GET is still the best method for fetching a simple representation of a resource. The problem starts when the query becomes large, nested, or too sensitive to fit well in the URI.
RFC 10008 points to common issues:
| GET problem | Practical effect |
|---|---|
| URI length limits vary across clients, proxies, and servers | The request can fail before it reaches the app |
| Nested structures need URL encoding | The API becomes fragile and hard to read |
| URIs often appear in logs, history, and bookmarks | Filters and sensitive data become more exposed |
| Every parameter combination looks like a different resource | Cache and resource identity become harder to model |
For simple filters, use GET. For complex queries with a body, QUERY is now the semantically correct option.
Why was POST not ideal?
POST accepts a body, so it became the usual escape hatch for complex searches. GraphQL, HTTP RPCs, and search endpoints often use POST even when the operation is read-only.
It works, but it loses protocol signal. To a client, proxy, cache, gateway, or generic library, POST can mean processing with side effects. Without endpoint-specific knowledge, it is not clear that retrying the request is safe.
Compare:
| Method | Body | Safe | Idempotent | Typical use |
|---|---|---|---|---|
| GET | No defined body semantics | Yes | Yes | Fetch a resource by URI |
| QUERY | Expected | Yes | Yes | Query with a body |
| POST | Expected | Not always | Not always | Submit processing or create something |
The value of QUERY is that it makes the safe query explicit.
How do caching and retries fit?
Cacheability is one of the main reasons QUERY matters. RFC 10008 defines QUERY as safe, idempotent, and cacheable, with rules for mapping a query to an equivalent resource.
In practice, a server can use headers like Content-Location or Location to give a URI to the result or to the equivalent query. After that, a client can use GET for that result when it makes sense.
Simple example:
QUERY /search HTTP/1.1
Host: api.example.com
Content-Type: application/json
Accept: application/json
{ "q": "http query", "limit": 10 }Response:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Location: /search/results/abc123
Cache-Control: public, max-age=300This keeps both ideas intact: the client sends rich query input in the body, and the server can still give the result an HTTP identity.
How can an endpoint advertise QUERY support?
Accept-Query is the header defined by RFC 10008 to advertise which query formats a resource accepts.
A response can show support like this:
Accept-Query: application/json, application/x-www-form-urlencodedThis matters because the method alone does not define the query language. The body can be JSON, form urlencoded, JSONPath, restricted SQL, an internal DSL, or another format. Content-Type must be explicit, and the server should reject missing or inconsistent media types.
A practical implementation rule:
| Case | Suggested status |
|---|---|
Missing Content-Type | 400 Bad Request |
| Unsupported media type | 415 Unsupported Media Type |
| Body inconsistent with the type | 400 Bad Request |
| Valid query that cannot be processed | 422 Unprocessable Content |
Accept asks for an unsupported response | 406 Not Acceptable |
When should an API use QUERY?
Use QUERY when the operation has these three properties:
- It is a read or query.
- It needs a body for filters, field selection, sorting, pagination, or a query language.
- It can be repeated without creating, changing, or deleting state on the target resource.
Good candidates:
- Search with nested filters.
- Read-only reports.
- Catalog queries with many facets.
- Internal APIs that use
POST /searchonly to carry filters. - Endpoints where automatic retry is useful.
Avoid QUERY when the operation:
- Creates a resource.
- Changes state.
- Starts a workflow.
- Records a business command.
- Depends on visible side effects.
If the client asks for a side effect, the method is still POST, PUT, PATCH, or DELETE.
Who benefits from QUERY?
The biggest beneficiaries of QUERY are teams that use POST for complex reads today and pay the semantic cost for it. The method helps when the operation is read-only, but the input is too rich for a URI.
| Who benefits | Why |
|---|---|
| API designers | They get a correct method for complex search with a body |
| Frontend and mobile teams | They can send rich filters without building huge URLs |
| SDKs and HTTP clients | They can separate safe queries from commands more clearly |
| Gateways, proxies, and CDNs | They can apply policy, cache, and retry with more context |
| Observability tools | Logs, traces, and metrics can distinguish complex reads from mutations |
| GraphQL, RPC, and tRPC | They get a possible better HTTP semantic for read procedures |
| AI agents and code tools | They can infer endpoint intent with less hidden documentation |
APIs that benefit the least are simple CRUD APIs where GET already describes the query well, and systems where proxies, clients, or gateways still block new methods. In those cases, QUERY can wait.
What changes for REST, GraphQL, RPC, gRPC, and tRPC?
API design gets an option that did not exist as a standard before: a query with a body, without pretending the operation is POST.
| Style | Before QUERY | What changes with QUERY |
|---|---|---|
| REST | GET for simple reads, POST for complex search bodies | QUERY /resources can represent complex search without side effects |
| GraphQL | POST for most requests, GET for small queries or persisted queries | Query operations could use QUERY in the future, but specs and clients need to adopt it |
| HTTP RPC | Many calls use POST even for reads | Read-only methods can get a clearer transport without abandoning RPC |
| gRPC | The protocol is defined over HTTP/2 with POST | Little changes soon. gRPC is its own contract over HTTP/2 |
| tRPC | Queries often use GET or POST, mutations use POST | QUERY would be a good transport for read procedures with large input |
For REST, the change is direct. Many endpoints like POST /search, POST /reports/query, or POST /products/filter exist only because GET does not carry large filters well. Those endpoints could become QUERY /search or QUERY /products.
For GraphQL, the change is attractive in theory, but not automatic. Current GraphQL over HTTP practice accepts POST, and allows GET for query operations. QUERY fits GraphQL query operations because they are reads with a body. Still, Apollo, Relay, gateways, CDNs, persisted query tooling, and the GraphQL over HTTP specification would need to treat it as an official transport before broad use.
For generic RPC, QUERY helps when there is a real split between read procedures and commands. A UserService.searchUsers call with no side effects is a candidate. An InvoiceService.closeInvoice call is not.
For gRPC, I would not expect a fast change. gRPC is not just "RPC using HTTP." It defines framing, trailers, the application/grpc content type, its own status model, and a mapping over HTTP/2. POST is part of that contract. The more likely change is not gRPC replacing POST with QUERY, but more HTTP-friendly RPC protocols, such as Connect, making better use of safe methods for idempotent calls.
For tRPC, the fit is natural because the framework already separates query and mutation. Today the HTTP transport uses GET and POST. A future version could map large-input queries to QUERY, while keeping mutations on POST.
What changes in HTTP/1.0, HTTP/1.1, HTTP/2, and HTTP/3?
HTTP semantics are separate from the transport version. QUERY is an HTTP method, so the idea applies to HTTP/1.1, HTTP/2, and HTTP/3. What changes is how likely the infrastructure is to accept the method without blocking it.
| Version | Where the method appears | Practical impact |
|---|---|---|
| HTTP/1.0 | Text request line: QUERY /search HTTP/1.0 | Works in theory, but this is the riskiest path because of old proxies |
| HTTP/1.1 | Text request line: QUERY /search HTTP/1.1 | Easy to understand, but middleboxes may block new methods |
| HTTP/2 | Pseudo-header :method = QUERY | Framing accepts HTTP semantics, but libraries and gateways need to recognize it |
| HTTP/3 | Same HTTP semantic model, transported over QUIC | Risk sits in libraries, gateways, and edge policy, not in the method name |
In HTTP/2, there is no textual request line like in HTTP/1.1. The method goes in the :method pseudo-header. That removes some parsing ambiguity, but it does not remove product policy. A gateway can still allow only GET, POST, PUT, PATCH, and DELETE.
There is also an HTTP/2 server push detail: clients can reject pushed requests for methods they do not recognize as safe. Since QUERY has a body and server push does not carry request content, this is not the main use case.
How should frameworks and languages adapt?
Interoperability is the main concern. The method is standardized, but real requests pass through clients, runtimes, proxies, firewalls, gateways, CDNs, observability tools, and libraries that may still block new methods.
The Node history shows the issue well. In January 2024, an issue reported that node:http returned 400 Bad Request for QUERY because the parser did not accept the method. This was not only an app detail. It was support at the HTTP layer.
The adoption order should look like this:
- The HTTP parser accepts
QUERY. - The router can register a
QUERYhandler. - The body parser reads a request body for that method.
- The HTTP client can send
QUERYwith a body. - CORS, cache, OpenAPI, tracing, WAF, and CDN understand the semantics.
| Layer | What is likely to change |
|---|---|
| Java | HttpClient already has method(String, BodyPublisher). Frameworks like Spring can use @RequestMapping once enums or extensions support it |
| Go | net/http supports custom methods through http.NewRequest and modern ServeMux routing |
| Node.js | The parser must accept the method. Then http, fetch, Express, Fastify, and Nest can route it |
| Spring | The natural path is support in RequestMethod and documentation for @RequestMapping with a body |
| NestJS | It may need its own route decorator, because @Query() already means query params. The route decorator name should avoid confusion |
| Express | It tends to follow the method list supported by its method package and the Node version in use |
| Fastify | It already has explicit extension through addHttpMethod, including hasBody |
| Apollo and Relay | They would need to treat QUERY as a valid GraphQL transport, not only GET or POST |
| Fetch | QUERY is not a forbidden method, but it is not CORS-safelisted. Expect preflight for cross-origin calls |
| OpenAPI | OpenAPI 3.2 already documents query as an operation |
Java example:
HttpRequest request = HttpRequest.newBuilder(URI.create("https://api.example.com/search"))
.header("Content-Type", "application/json")
.method("QUERY", HttpRequest.BodyPublishers.ofString(json))
.build();Go example:
req, err := http.NewRequest("QUERY", "https://api.example.com/search", body)And on servers with the modern ServeMux:
mux.HandleFunc("QUERY /search", queryHandler)Fetch example:
await fetch("https://api.example.com/search", {
method: "QUERY",
headers: {
"Content-Type": "application/json",
"Accept": "application/json",
},
body: JSON.stringify({ filters: { status: "active" }, limit: 20 }),
});Fastify example:
fastify.addHttpMethod("QUERY", { hasBody: true });
fastify.route({
method: "QUERY",
url: "/search",
handler: async (request, reply) => {
return reply.send(await search(request.body));
},
});In browser JavaScript, the main concern is the full path across Fetch, Cross-Origin Resource Sharing, service workers, gateways, and infrastructure. Before exposing QUERY in a public API, test the whole path:
- HTTP client.
- Server runtime.
- Reverse proxy.
- Load balancer.
- CDN.
- Web Application Firewall or firewall.
- Logs, tracing, and metrics.
Being an RFC does not mean every tool in the path already treats QUERY as routine.
How would I implement QUERY today?
I would start with controlled adoption. For a public API, I would keep GET and POST where they are still needed, then add QUERY first to endpoints where the semantic gain is clear.
A safe plan:
- Pick a search endpoint that uses POST today but is read-only.
- Implement
QUERYwith the same body contract. - Require
Content-Type. - Return
Accept-Query. - Define caching only when variation by body is well modeled.
- Test client, proxy, CDN, and logs.
- Document a POST fallback while infrastructure catches up.
Example with curl:
curl -X QUERY https://api.example.com/search \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
--data '{"filters":{"status":"active"},"limit":20}'For a real product, I would also add integration tests through the same HTTP port used in production. Calling the handler directly is not enough. The risk is in the network path.
What is the practical rule?
The rule is: use GET when the URI describes the query well, use POST when the operation may have side effects, and use QUERY when the query needs a body but remains safe and idempotent.
QUERY is a small syntax change, but a large protocol signal. It lets the API, client, and infrastructure understand the request intent without relying on local convention.
References
- RFC 10008: The HTTP QUERY Method
- HTTPWG draft: The HTTP QUERY Method
- Node.js issue #51562: Support for QUERY method
- Kevin McDonald: HTTP QUERY and Go
- RFC 9110: HTTP Semantics
- RFC 9113: HTTP/2
- Fetch Standard
- GraphQL: Serving over HTTP
- gRPC over HTTP/2
- tRPC HTTP RPC Specification
- OpenAPI 3.2 HTTP Methods
- Java HttpRequest.Builder
- Spring Request Mapping
- Fastify addHttpMethod
TL;DR: QUERY is the HTTP method for safe queries with a body. It does not replace GET or POST. It gives the right semantics to complex searches that use POST today only because GET does not carry that input well.
Written by AI, reviewed by Thiago Marinho
June 21, 2026 · Brazil